La gestion traditionnelle des infrastructures a atteint ses limites. Quand le système d’information est le cœur de l’entreprise, chaque minute d’arrêt se paie cher : 14 056 $ par minute en moyenne, jusqu’à 23 750 $ pour les grandes organisations et plus de 90 % des entreprises estiment qu’une heure de panne leur coûte au minimum 300 000 $ (EMA Research & ITIC, 2024).
Face à cette réalité, continuer à surveiller ses infrastructures à la main, avec des seuils statiques et des actions manuelles n’est plus envisageable.
C’est là qu’intervient l’AIOps. Pas comme une tendance technologique de plus mais comme une réponse concrète à un problème qui coûte cher, épuise les équipes, et s’aggrave à mesure que les architectures se complexifient. Pour les équipes SRE (Site Reliability Engineering), l’IA devient le copilote qui ne dort jamais, ne se fatigue pas, et voit ce que l’humain ne peut plus voir seul.
Observabilité : l'enjeu de la complexité
La transition vers le Cloud et les microservices a transformé nos infrastructures en puzzles géants. Cette fragmentation crée trois obstacles majeurs pour les organisations :
Croissance exponentielle des flux
La fragmentation des systèmes multiplie mécaniquement la production de données spécifiques à chaque service. Cette prolifération de signaux (logs, métriques, traces) crée une saturation d’information, rendant l’analyse de plus en plus complexe.
Fragmentation humaine
La gestion étant répartie entre de multiples équipes, maintenir une visibilité globale sur la santé du système devient un défi quotidien.
Silotage des données
L’information est dispersée entre divers services et régions, ce qui rend la corrélation des incidents longue et complexe.
Comprendre le système : Les trois piliers de l’observabilité
L’observabilité permet de déduire l’état d’un système complexe en analysant trois flux de données complémentaires :
- Métriques : Les indicateurs de santé chiffrés (latence, taux d'erreurs, volume de requêtes).
- Traces : Le suivi d'une requête, de bout en bout, à travers tous les services.
- Logs : Le journal détaillé des événements survenus.
Le volume de données généré aujourd’hui dépasse les capacités d’analyse humaine. Pour un service SaaS standard, les chiffres sont vertigineux :
- Logs : Plusieurs téraoctets générés chaque jour.
- Traces : Des millions de parcours enregistrés par heure.
- Métriques : Plus de 10 000 courbes de performance à surveiller en continu.
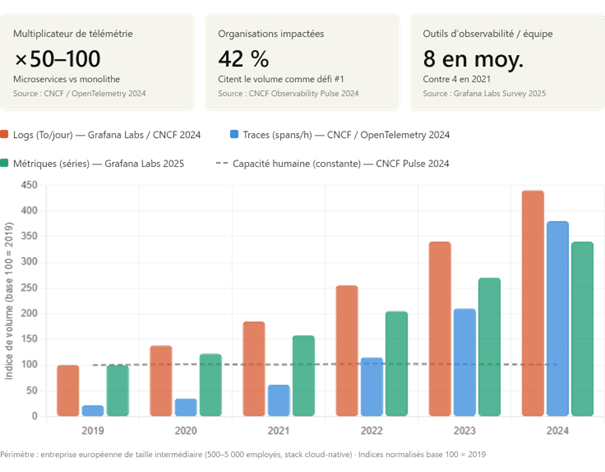
Cette surabondance provoque une saturation des alertes (alert fatigue). Le signal critique, celui qui annonce la panne réelle, se retrouve souvent noyé dans un bruit de fond technique incessant, rendant le travail des équipes SRE et DevOps épuisant et imprécis.
L’AIOps
un levier de performance opérationnelle
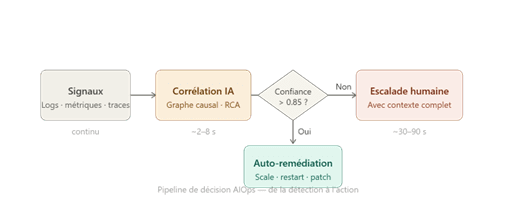
L’AIOps agit comme une couche d’intelligence supérieure qui transforme la gestion des incidents en passant d’une analyse manuelle à une réponse automatisée.
Analyse et corrélation à grande échelle
Là où l’humain est limité par sa capacité à croiser les informations, l’IA analyse simultanément des milliers de flux (métriques, logs, traces). Elle ne se contente pas de surveiller des seuils fixes ; elle identifie des liens entre des événements isolés pour détecter des schémas de défaillance complexes, invisibles pour les outils traditionnels.
Détection préventive des signaux faibles
L’AIOps excelle dans le repérage des anomalies marginales qui précèdent les pannes majeures. En analysant les dérives comportementales (ex : une légère hausse de latence ou une baisse inhabituelle d’appels sur un service), le système alerte les équipes avant même que l’utilisateur final ne ressente un impact.
Accélération du diagnostic
L’un des gains majeurs réside dans l’automatisation de l’analyse de cause racine (Root Cause Analysis). Au lieu de mobiliser plusieurs experts pour enquêter, l’IA rassemble les preuves techniques en temps réel et pointe directement le composant défaillant. Cette précision réduit drastiquement le temps de réparation ou MTTR (Mean Time to Repair) et libère les équipes des tâches répétitives.
Une étude publiée sur Research Square montre que l’adoption de l’AIOps améliore la détection des incidents de 35 %, la précision du diagnostic de 25 %, et réduit le MTTR de 40 %. (Research Square, 2025).
Révolution des post-mortems et capitalisation des incidents
Le post-mortem devient un moteur de progression continue grâce à trois piliers :
Objectivité factuelle
L’IA génère automatiquement une chronologie précise de l’incident, sans les oublis ou biais propres aux rapports manuels.
Apprentissage dynamique
Chaque incident résolu enrichit une base de connaissances. Le système apprend des diagnostics passés pour accélérer les résolutions futures.
Culture de la transparence
Des rapports clairs et détaillés facilitent la communication avec les parties prenantes, prouvant que l’incident est maîtrisé et que des mesures préventives sont en place.
L’humain au cœur du dispositif
L’IA ne remplace pas l’ingénieur, elle agit comme un copilote. Si elle traite la masse de données pour fournir des preuves, c’est l’équipe humaine qui définit les actions correctives durables. La performance de l’IA reste cependant indissociable de la qualité de l’observabilité initiale : sans données fiables en entrée, l’analyse reste inefficace.
Déploiement et opérations proactives
Une implémentation progressive
L’adoption de l’AIOps n’est pas un remplacement brutal, mais une montée en compétence du système. Elle suit généralement trois phases clés :
Mode Observation (Shadow Mode)
Pendant 2 à 4 semaines, l’IA analyse les flux sans déclencher d’alertes afin de calibrer ses modèles et d’éviter les faux positifs.
Réduction du bruit
Une fois stable, l’IA commence à regrouper les alertes similaires pour ne présenter qu’un seul incident consolidé aux équipes.
Automatisation de bas niveau
Mise en place de remédiations automatiques pour les tâches simples et répétitives (ex: redémarrage d’un service saturé).
Vers une stratégie proactive et prédictive
L’aboutissement de l’AIOps réside dans sa capacité à transformer la gestion des incidents : passer de la réaction à l’anticipation. Pour les organisations les plus matures, identifier une défaillance imminente et intervenir avant tout impact utilisateur est désormais une réalité opérationnelle.
Forecasting et gestion capacitaire
L’exploitation de modèles prédictifs (tels que Prophet, SARIMA ou LSTM) permet d’anticiper la saturation des ressources critiques. En projetant l’évolution des séries temporelles, le système peut déclencher un provisionnement préventif bien avant la rupture de service.
Analyse d’impact des changements
L’AIOps assure une corrélation systématique entre les événements de déploiement (releases, modifications de configuration) et la stabilité de l’infrastructure.
Le Change Impact Score
En croisant ces flux en temps réel, le système génère un score de risque associé à chaque modification. Cet indicateur permet d’évaluer instantanément la dangerosité d’une mise en production et d’accélérer la prise de décision en cas de dérive des performances.
Netflix Telltale
Netflix a utilisé cette philosophie avec sa solution maison Telltale. Le système ne surveille pas les pannes : il les anticipe. En corrélant en temps réel les signaux de dégradation à travers des centaines de microservices, il prédit l’impact sur l’expérience utilisateur avant que la moindre alerte classique ne se déclenche. Plus fort encore, il ne se contente pas de reconnaître des incidents déjà vu mais raisonne à partir des modèles causaux appris lors des incidents passés pour faire face à des configurations entièrement nouvelles.
L’AIOps ne remplace pas l’expertise humaine mais l’amplifie. En automatisant l’analyse des données de masse, elle libère du temps pour les ingénieurs (SRE/DevOps) afin qu’ils se concentrent sur l’architecture et l’amélioration continue du système.
L'IA comme co-pilote de la fiabilité
L’AIOps n’est pas une mode passagère ni une promesse marketing. C’est la réponse structurelle à un problème fondamental : la complexité des systèmes modernes a dépassé la capacité humaine de supervision en temps réel. Les volumes de données, la vitesse des changements et l’interconnexion des services rendent impossible toute approche purement manuelle à grande échelle.
Pour autant, l’AIOps n’est pas une solution magique. Son efficacité dépend directement de la qualité des données en entrée, de la rigueur de la phase d’apprentissage, et de l’engagement des équipes à l’alimenter de feedback. Un outil AIOps déployé sur une observabilité médiocre produira des résultats médiocres.
La trajectoire est claire : les équipes SRE et DevOps qui adoptent cette approche, en commençant par réduire le bruit, en automatisant progressivement les remédiations à faible risque, et en visant à terme l’analyse prédictive gagnera en sérénité opérationnelle, réduisent leur MTTR, et libèrent de la bande passante cognitive pour ce qui compte vraiment : construire des systèmes plus résilients.
L’objectif final n’est pas de remplacer l’intelligence humaine, mais de l’amplifier là où elle est la plus précieuse.
Forecasting et gestion capacitaire
L’exploitation de modèles prédictifs (tels que Prophet, SARIMA ou LSTM) permet d’anticiper la saturation des ressources critiques. En projetant l’évolution des séries temporelles, le système peut déclencher un provisionnement préventif bien avant la rupture de service.
Analyse d’impact des changements
L’AIOps assure une corrélation systématique entre les événements de déploiement (releases, modifications de configuration) et la stabilité de l’infrastructure.
Le Change Impact Score
En croisant ces flux en temps réel, le système génère un score de risque associé à chaque modification. Cet indicateur permet d’évaluer instantanément la dangerosité d’une mise en production et d’accélérer la prise de décision en cas de dérive des performances.
plus d'insights

l’IA renforce le consultant, le consultant donne du sens à l’IA
company newsdigital solutionsgovernance & service managementquality assurance & testing
June 09, 2026

De zéro à 100 tests en 2 jours avec l’IA
quality assurance & testing
May 18, 2026

Optimisez votre ERP Infor Cloud Suite / M3 avec les solutions Tricentis
quality assurance & testing
November 02, 2025